
Without big data, you are blind and deaf and in the middle of a freeway.
Guess what? This spring was about big things in the WebSpellChecker AI 🤖realm!
We’re super excited to announce that our NLP team has participated in the UNLP workshop (The Second Ukrainian Natural Language Processing Workshop), a part of the 17th EACL 2023, and introduced the improved custom RedPenNet approach for Grammatical Error Correction. Normally, we don’t talk much about the tech behind the curtains (it’s a kind of a big secret — shhh!), but some things are worth unveiling. So, embrace yourself; a lot of NLP info is coming.
The background of our participation at UNLP 2023
First, let’s talk a bit about the event.
The Second Ukrainian Natural Language Processing Workshop (UNLP 2023) is an event that focuses on advances in Ukrainian Natural Language Processing. The goal is to bring together leading academics, researchers, and practitioners who work on the Ukrainian language or do cross-Slavic research that can be applied to the Ukrainian language.
The workshop was held online in conjunction with the 17th Conference of the European Chapter of the Association for Computational Linguistics (EACL 2023). The UNLP 2023 finished as a platform for discussion and sharing of ideas, a collaboration between different research groups, and a hub for the Ukrainian research community, which improved its visibility.
In 2022, the world learned about the brave souls of Ukrainians 🇺🇦 Now it’s time for us to show our NLP potential.
Besides the research materials, the workshop featured the first Shared Task on Grammatical Error Correction for Ukrainian, which had two tracks: GEC-only and GEC+Fluency.
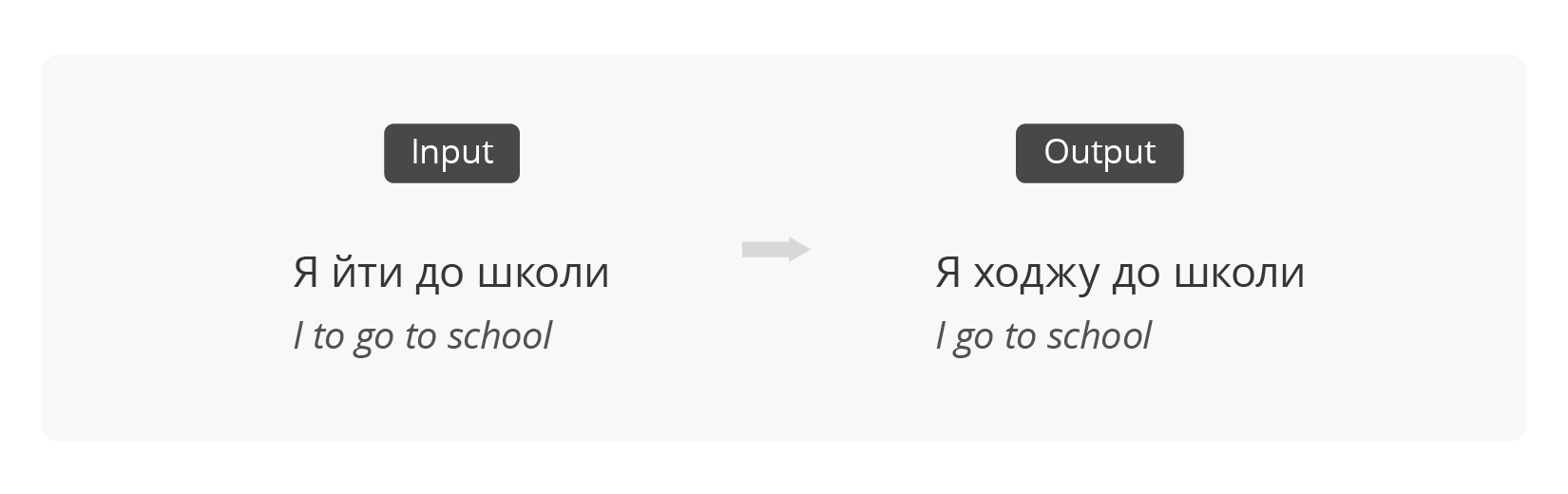
GEC-only
Grammatical error correction (GEC) is a task of automatically detecting and correcting grammatical errors in written text. GEC is typically limited to making a minimal set of grammar, spelling, and punctuation edits so that the text becomes error-free. For example:
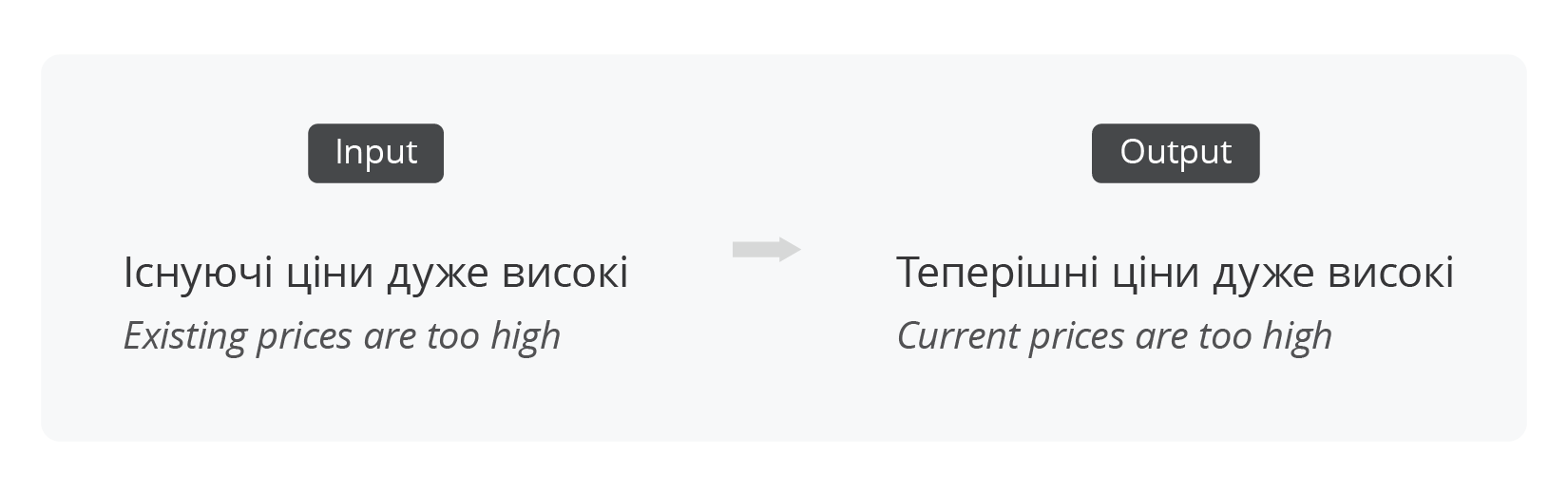
GEC+Fluency
Fluency correction is an extension of GEC that allows for broader sentence rewrites to make a text more fluent—i.e., sounding natural to a native speaker. Fluency corrections are more subjective and may be harder to predict. The GEC+Fluency task covers corrections for grammar, spelling, punctuation, and fluency. For example:
Our NLP team has participated in both tracks with a main focus on Track 2 and won incredible results 😎
- For Track 1 (GEC), we achieved a 0.6596 F0.5 score
- For Track 2 (GEC+Fluency), we got a 0.6771 F0.5 score
But more importantly, we’ve introduced our improved architecture to Grammatical Error Correction Task with a very promising title — RedPenNet.
Ladies and Gentlemen, this is RedPenNet, a custom approach aimed at reducing architectural and parametric redundancies presented in specific Sequence-To-Edits models, preserving their semi-autoregressive advantages. Our NLP experts started working on RedPenNet in 2019 when they offered a multi-headed architecture based on BERT for GEC tasks within the previous competition, BEA 2019. Among the main advantages of our solution at that time was increasing the system productivity and lowering the processing time while keeping a high accuracy of GEC results. This time we have gone even further and showcased an improved version of the RedPenNet model within the Shared Task that brings more capabilities and benefits for our clients.
RedPenNet for Grammatical Error Correction: Outputs to Tokens, Attentions to Spans
Okay, what is RedPenNet?
School years inspired us to create this unique architecture. In particular, the memories of how the teacher corrected mistakes in the students’ notebooks of their students with a red pen ✍️. Mmmm, what a cool time it was!
In layman’s terms, RedPenNet acts like a diligent school teacher. It uses a pre-trained HuggingFace MLM encoder and a shallow decoder to generate replacement tokens and edit spans. The attention weights pinpoint the edit locations, like a teacher visually marking areas.
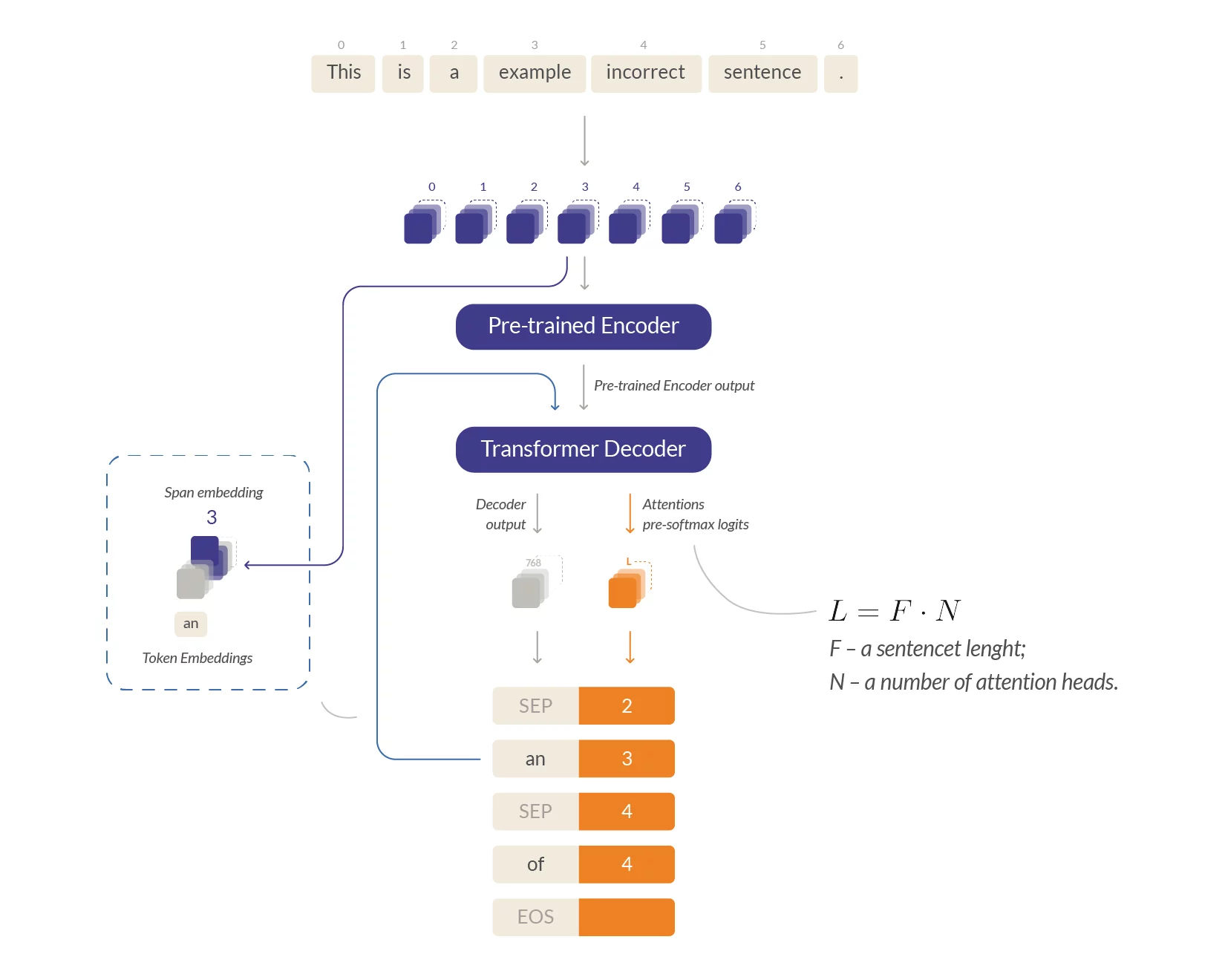
The advantage: RedPenNet can execute various source-to-target transformations with minimal autoregressive steps, enabling effective resolution of GEC cases involving interconnected and multi-token edits.
The limitation: Due to the customized architecture of RedPenNet, ready-made solutions for data preprocessing, training, and fine-tuning are unavailable, unlike common tasks such as classification or sequence-to-sequence. Consequently, convenient tools like the HuggingFace infrastructure or cloud platforms cannot be employed for swift model fine-tuning and deployment.
More details on the improved RedPenNet architecture can be found in the article “RedPenNet for Grammatical Error Correction: Outputs to Tokens, Attentions to Spans.” Putting theory aside, how does it work practically? And what perks do these improvements bring to our clients?
During the competition, the WSC NLP team obtained great results:
- We tested the improved BERT architecture based RedPenNet model on the English corpus we deployed during the previous competition — BEA 2019. The result achieved was — a 0.7760 F0.5 score 💪 By and large, the current RedPenNet model deployed for AI English, German, and Spanish was improved. Before, there was a bug reported by many of WSC clients: the model gave unsynchronised suggestions and spans, and sometimes suggestions were offered to the wrong positions. Now, the model can generate the position and then — the suggestion.
- Also, during the competition, we created an automated mechanism that synchronizes the usage of a combo of tools, aka “generators” of neutral networks — AWS SageMaker and Google Colab. And it was freaking good! Gonna start using them regularly 💪
- Last but not least, for any separate suggestion, now we have a probability that could improve the model score. These probabilities may be configurable, which suggests a new field for building new features like AI grammar autocorrect.

Of course, these results inspired us to plans and perspectives. Soon at WebspellChecker:
- The updated RedPenNet model will be used for other languages, primarily for English. Next, come German and Spanish. This may considerably improve their performance score. For this purpose, now we’re teaching the English model and will compare its score with the current one.
- As for our native language, Ukrainian, we already have a feasible model, but the new model requires tokenization changes on the application server backend. Currently we deploy a traditional dictionary-based spell checker for Ukrainian, but having a new model will enable us to build an AI-driven engine for our native language and offer it for free within the subscription to WProofreader that is available as browser extension.
On a side note
Being Ukrainian means fighting and contributing to the national identity. The Ukrainian language, as we call it, “solovyina mova 🐦”, is our DNA, and when we came across the UNLP 2023, our decision to participate was immediate. But… the moment we decided upon our participation we were short of time. Only 3 weeks were left before the draft paper submission deadline. So, unlike other participants, we had less time, although, in fact, it pushed us to deliver great results.
Our part in the Shared Task can help improve the performance of the WebSpellChecker product portfolio by applying state-of-the-art techniques for grammatical error correction and fluency enhancement to various text types and domains. The outcome can also benefit the development of AI-driven Ukrainian that will take pride of place in our support list.
Moreover, participating in such events, we boost the visibility of the Ukrainian NLP community and foster potential collaborations with other researchers or organizations.

 Tech
Tech

 Français
Français


 Linguistics
Linguistics Deutsch
Deutsch