Ah, the spring — that magical time of fresh starts… and MASSIVE UPGRADES 😄
We’re excited to introduce you to the latest and greatest version of our core architecture for grammatical error correction tasks (GEC) — RedPenNet v2!
For a while now, we’ve been chasing one big goal: fixing the basic problem in every grammar checker area — picking between speed and quality. On the one hand, you’ve got autoregressive neural machine translation (NMT) models that nail the context but crawl at a snail’s pace. On the other hand, you’ve got token-based models. They’re lightning-fast, but often miss the point.
So we thought, why choose at all?
With RedPenNet, we finally built a hybrid that blends the best of both worlds. You get smart, accurate, context-aware suggestions, and you get them instantly. Plus, WProofreader is now way more stable and reliable — we’ve already fixed some of the most common issues users faced and we’re continuing to improve its performance.
Alright, let’s see what’s new! We’ll walk you through the latest upgrades and show how they make writing and editing way easier.
Understanding RedPenNet’s custom approach to GEC
First off, if you still don’t know what RedPenNet is or what we’re talking about here, we recommend checking out our architecture presentation for GEC tasks that we did at UNLP 2023. So if you’re into deep dives and all that low-level architecture stuff — welcome.
RedPenNet is a grammar correction architecture we built at WebSpellChecker. It powers our AI-driven GEC engine. The name kinda gives it away — we totally channeled that old-school red pen vibe. You know, when a teacher would grab that red pen and mark up your notebook with every little mistake? Yeah, that. Except now, we’ve swapped out the ink for a language model. And the teacher? It’s an algorithm that really gets context — and knows how to fix mistakes properly.
Today we’re gonna walk you through what’s new in version 2.0, how we leveled up the model and why these changes make your spellchecker way smarter. Let’s go step by step through the biggest upgrades we’ve made.
- Word vector-based improvements for better correction precision
The main improvement in our new version is how RedPenNet analyzes and understands text. Previously, the model would first figure out where to place the correction, then decide what exact text to suggest for the change. But now, it picks the fix first and uses that info right away to nail down which part of the sentence actually needs swapping out. After that, the model kind of “holds it in its mind” the last word it fixed and uses that fresh info to better decide which mistake to tackle next.
This kind of memory about previous changes helps it:
- Work more accurately and avoid extra fixes.
- Keep your text’s meaning and structure intact.
- Save time processing the text and suggesting corrections.
Thanks to this improvement, WProofreader can now better understand what you’re trying to say. So, it offers more natural corrections. It’s like having an experienced editor who pays attention to both the overall context of your sentence and the meaning of each individual word.
- Bigger training data for better accuracy
Another reason why the corrections were more accurate is that we started using more data to train the model. This helps it understand the context in which words are used.
It works like this: the more examples the model sees, the better it understands how words work in different situations. This has made our tool even better at giving more precise and correct fixes, even for academically complex things.
So now, the model is way better at figuring out when a correction actually matters and when it can just leave it alone. Before, if a sentence had a few mistakes, the model sometimes made changes that didn’t really make sense. It was more like surface-level edits than real improvements.
Now, it’s way more picky. It only makes changes when they actually improve the text. This has had the impact that WProofreader is now much better at picking up dialects and context.
- Fixed the issue with shifted suggestions
Also, one of the biggest improvements in the new RedPenNet is fixing what we used to call “shifted suggestions.” That happened when a sentence had too many mistakes. The model would kinda lose track of the structure and mess up the logic of the whole thing. Sometimes it even jumbled the words around in weird ways, which made the sentence hard to read.
We’ve put a lot of work into fixing this issue, and now it appears much less frequently. While we’re still working on fully getting rid of it, you’ll definitely notice the difference between the old and new generation of RedPenNet.
The model got way better at catching the right word order and keeping everything in sync. It understands how the parts of a sentence need to fit together, so the edits make way more sense now.
Beyond that, of course, we’ve made some other major changes to the corrections we offer to users:
| Improvement | Description |
| Better punctuation handling | The model now handles hyphens, apostrophes and other punctuation marks way better. |
| Increased accuracy with prepositions | The model now processes prepositions and the context they’re used in more precisely. |
| Fixing sentence displacement issues | Displaced sentences, which were a problem in the previous version, barely pop up anymore. |
| Reducing false positives | Architectural tweaks helped us cut down on false positives, making the output more precise. |
| Capitalization | Capitalization of letters in sentences has been improved. |
| Grammatical forms | Subject-verb agreement and past tense forms of irregular verbs are now smoother. |
| Contextual understanding | Thanks to improvements in vector representations, the model gets the context better than ever before. |
And we’re not stopping here 😉
We’re training it more on medical texts and long sentences. Also, now we’re tightening up its handling of plural forms and reducing any gender bias. All this helps us keep the balance between accuracy and natural flow without losing the liveliness of the language.
Let’s see how all this actually works and makes using WProofreader feel way easier.
How RedPenNet compares to other AI-driven GEC solutions
We’re gonna compare how the updated RedPenNet stacks up against some of the big names in grammar correction. We’ve already covered the LLMs behind these tools in our article Behind colorful lines: How digital proofreaders classify writing errors. So let’s skip the basics and jump right into the comparison.
Take an example:
Arthur kept asking to staff if his dish are spice free, staff reassured the him that your meal will completely be without seasoning.
Here, we’ve got several types of mistakes that our updated RedPenNet handles with ease.
| Type of correction | Explanation |
| to staff → staff | In English, the preposition “to” is not required after the verb “ask” if it is a question |
| are → was | Since the sentence refers to a past event (Arthur asking about the dish), we need to use the past tense “was” instead of the present tense “are” for subject-verb agreement. |
| spice free → spice-free | When two words combine to describe something, we use a hyphen to make it a compound adjective. |
| the him → him | The extra article “the” before the pronoun “him” is unnecessary. It violates the norm of grammar. |
| your → his | The meal belongs to Arthur, so we need to use “his” instead of “your.” |
| will → would | Since the sentence refers to a past situation, we use “would” (past tense) instead of “will” (future tense). |
| completely be → be completely | Here “be” is placed after “would” because “would” is an auxiliary verb that requires the main verb in infinitive form (i.e. without “to”). |
Now take a closer look at how it compares to other AI-driven grammar correction tools. We’ll focus on key differences in performance, error detection, and processing efficiency. We’ll be comparing the free versions of digital spellcheckers.
Sapling
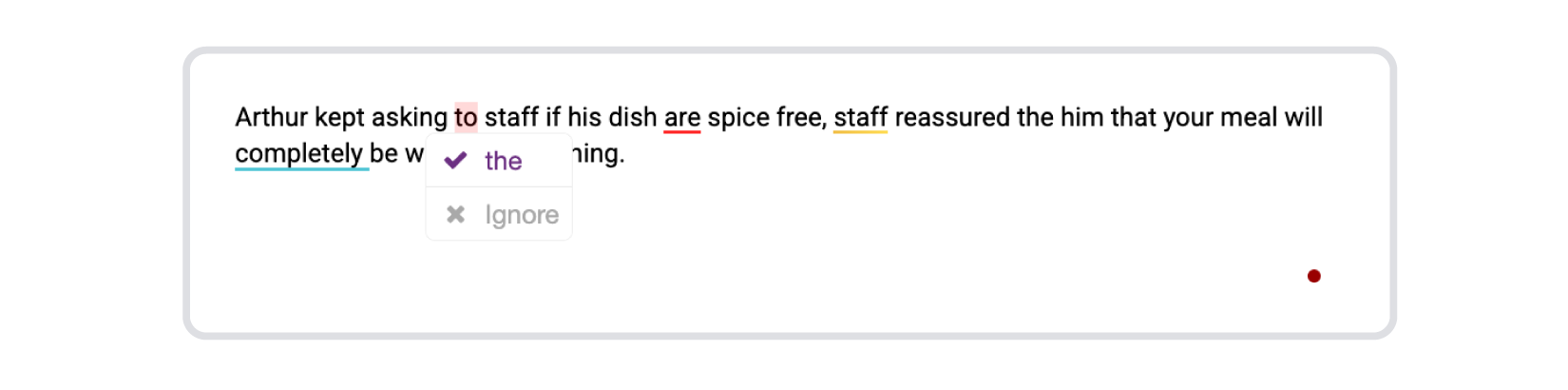
Sapling got through this task with some issues, catching four out of the seven mistakes. It corrected “to staff” to “the staff,” but in this case, the preposition “the” isn’t needed after “ask.” We’re talking about the staff in general, not a specific group. Then it changed “are” to “was,” which was correct. Next it added “and the staff,” but the conjunction “and” here seems unnecessary and makes the sentence a bit clumsy. Finally, Sapling suggested removing “completely,” saying it was redundant and weighing the sentence down. Of course, this depends on the writer’s perspective, but it’s not a critical mistake in our case.
Sapling fell short in key areas. It missed some basic grammatical issues and instead of focusing on those, it veered off into stylistic suggestions.
Grammarly
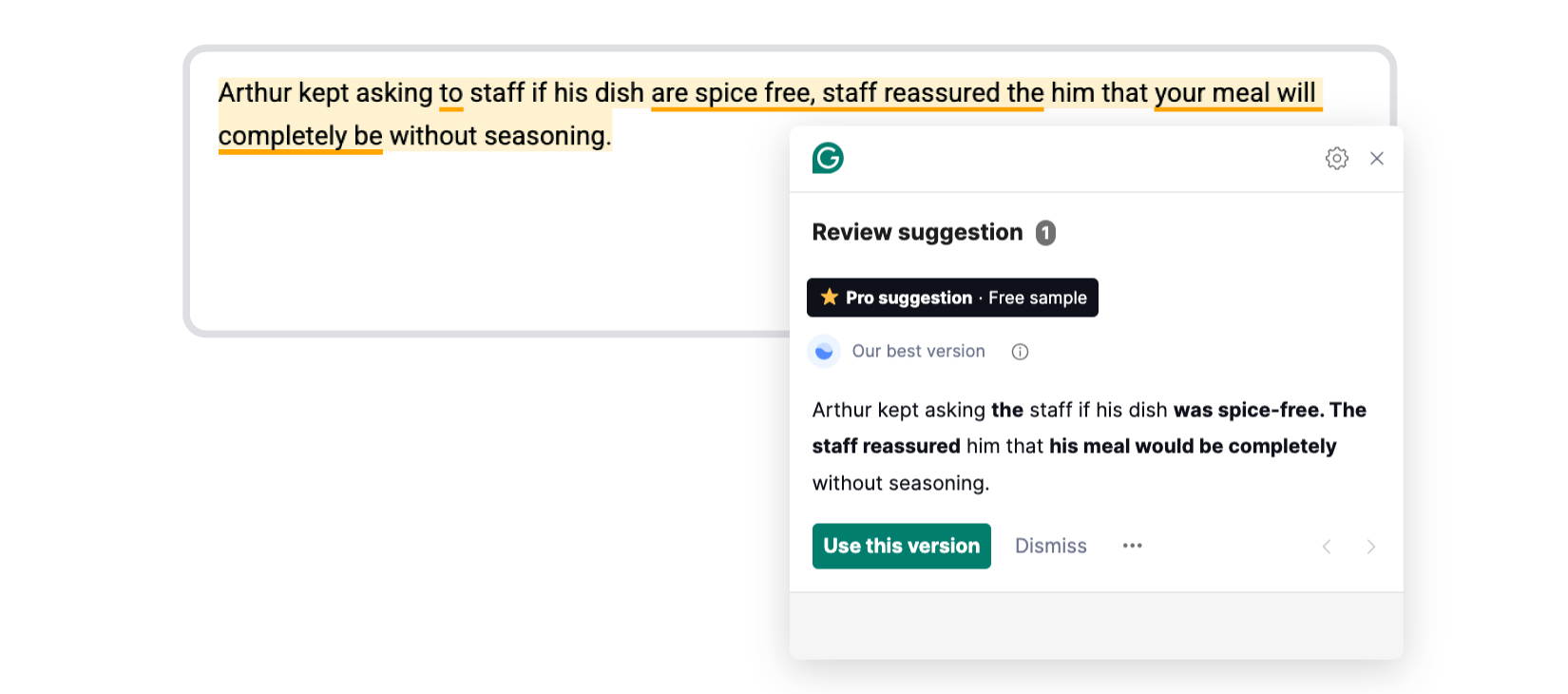
Grammarly highlighted all seven issues. Same as Sapling, it changed “to staff” to “the staff,” but that’s off — “ask” doesn’t need a preposition in this case. Also, here’s the catch — on the free plan, it only offers one AI rewrite. So, unless you pay, you won’t get full access to its advanced suggestions. That’s a serious limit when you’re dealing with more than one tricky sentence.
Linguix
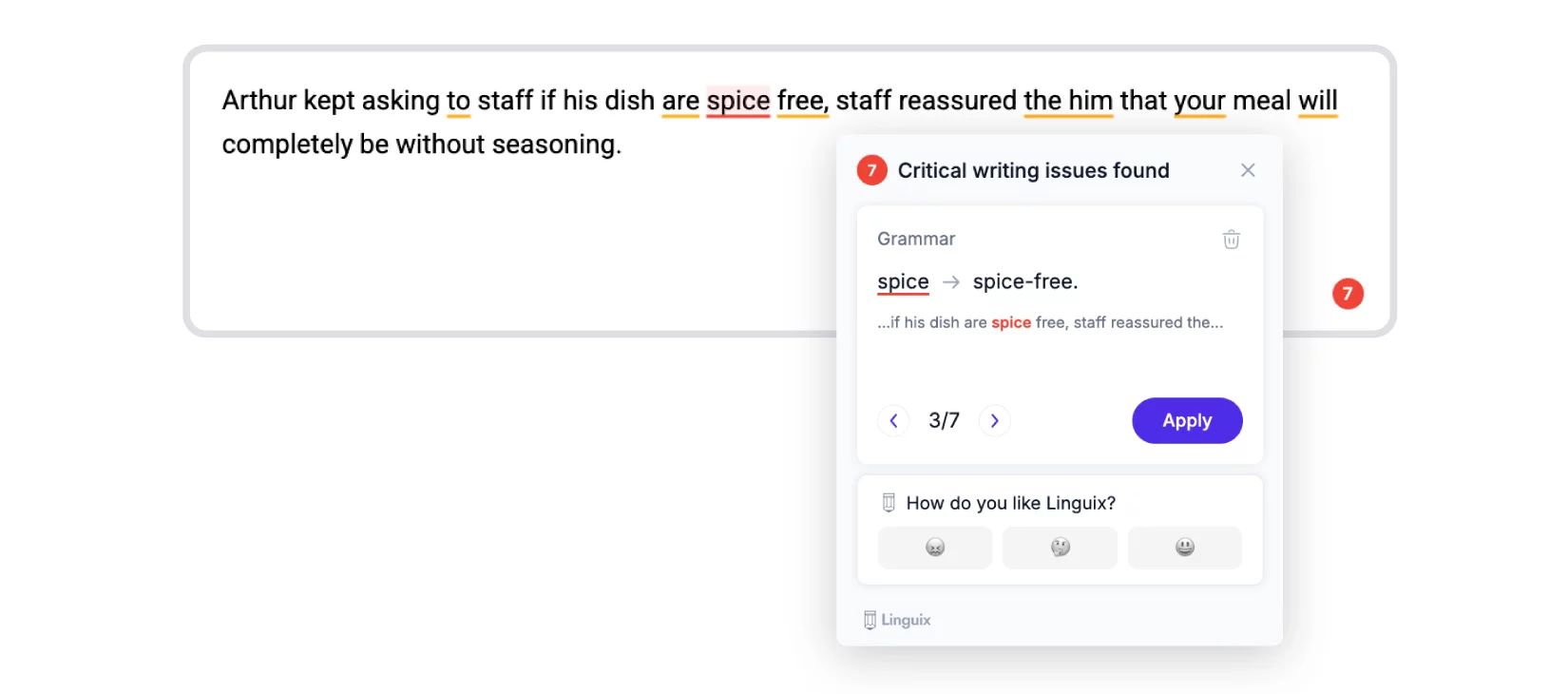
Linguix in its free version only caught the words “spice” and “free” separately, suggesting changing “spice” to “spice-free.” It’s unclear how it would handle the word “free” though. Also, it does see other errors, but they are only available for correction in the premium version. So, we don’t know what corrections it offers. And it completely ignored the error with the correct placement of the verb “be” at the end of the sentence. So, while Linguix found some issues, it still left quite a few on the table.
WProofreader
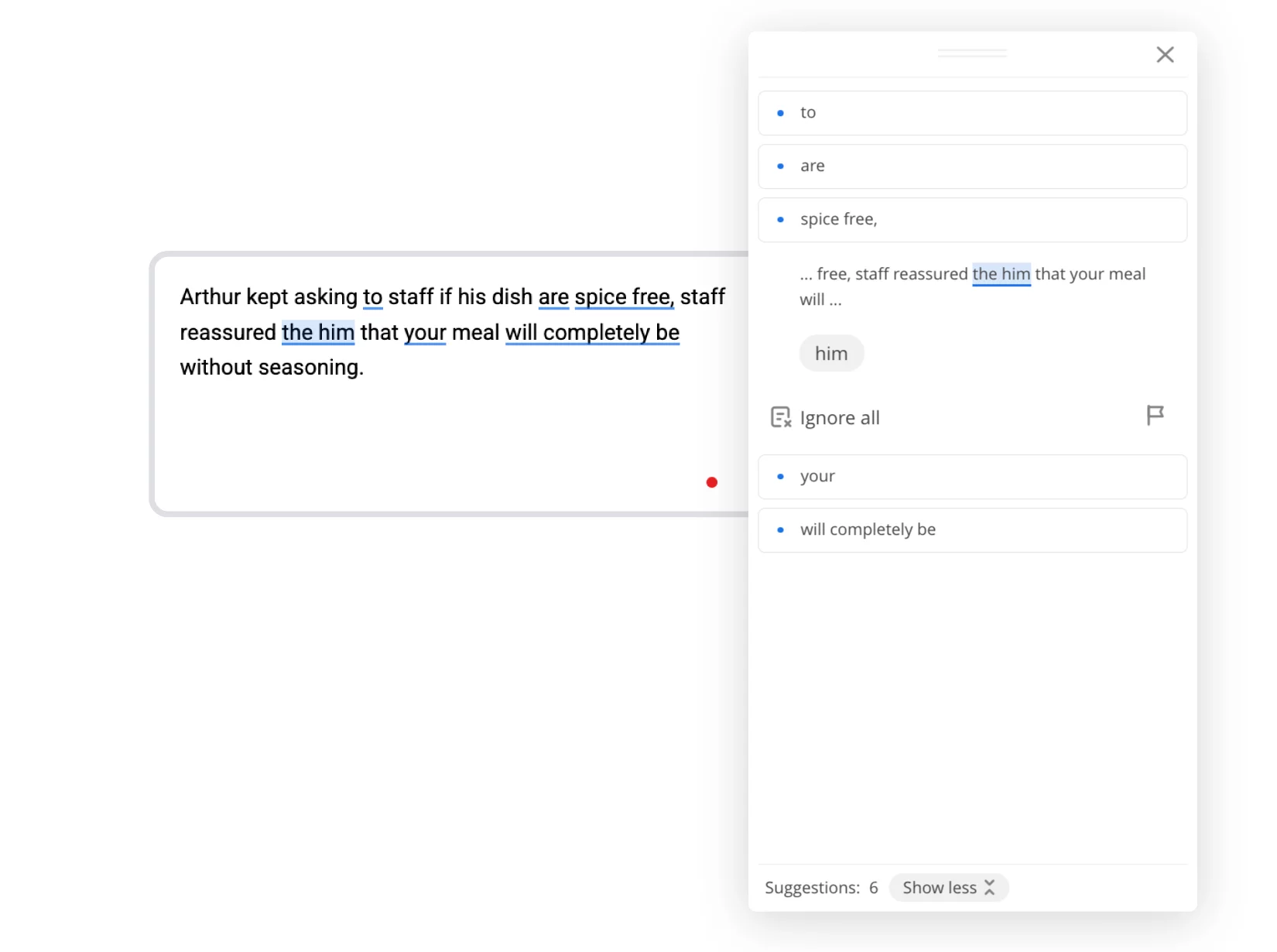
WProofreader nailed it! It caught all the mistakes in our example and that’s all thanks to the recent upgrades we made to the model. These improvements let it not only spot typical grammar mistakes, but also understand the context, which makes the corrections way more accurate. Now WProofreader looks at the entire sentence, catching the obvious grammar issues first — and then digging deeper to catch trickier stuff like:
- incorrect article use
- wrong word order
- tense agreement errors
- preposition issues
In the end, our tool came up with fixes, showing off its accuracy and attention to detail. Unlike other tools, which might miss these things, RedPenNet’s got it all covered.
However, we should remember that AI’s always kinda like a “black box.” Even the newest RedPenNet model isn’t perfect — it can still mess up sometimes. We don’t claim to have it all figured out, but we work hard every day to get better. We listen to our users, add more training data, and try different tricks to fix writing mistakes. We keep grinding on upgrades, and we’ve already lined up fixes for the known issues in RedPenNet 2.2 😉
Besides, WProofreader also has a bunch of other advantages that’ll make your content proofreading a breeze.
WProofreader SDK and browser extension

WProofreader is a secure and all-in-one digital spellchecker that supports over 20 languages. You can pick the version that fits your workflow best:
✅ WProofreader SDK is perfect for developers, website owners and anyone working in web development. It’s a ready-made solution for spell checking in WYSIWYG editors like CKEditor, Froala, TinyMCE, and Quill. You can also get it as a standalone API. Whether you prefer self-hosting (on-prem or in a private cloud) or prefer the cloud deployment option, it’s flexible enough to work with either.
✅ WProofreader browser extension is a great choice for individual users who write documents, emails or other content in multiple languages. It checks spelling and grammar for both individuals and teams. On the free plan, your requests go through our cloud setup. When you decide to upgrade to the Business plan, you’ll be able to deploy it on your own servers.
With any version of WProofreader you choose, you will have access to:
- Real-time correction in 20+ languages, including AI-based English, German, and Spanish
- Autocorrect and autocomplete features for English and dialects
- Automatic language detection
- Organization-wide and user custom dictionaries
- Specialized medical lexicon for English, Spanish, French, and German
- Legal lexicon is available for English and its dialects
- Inclusive language recommendations
- Custom rules builder
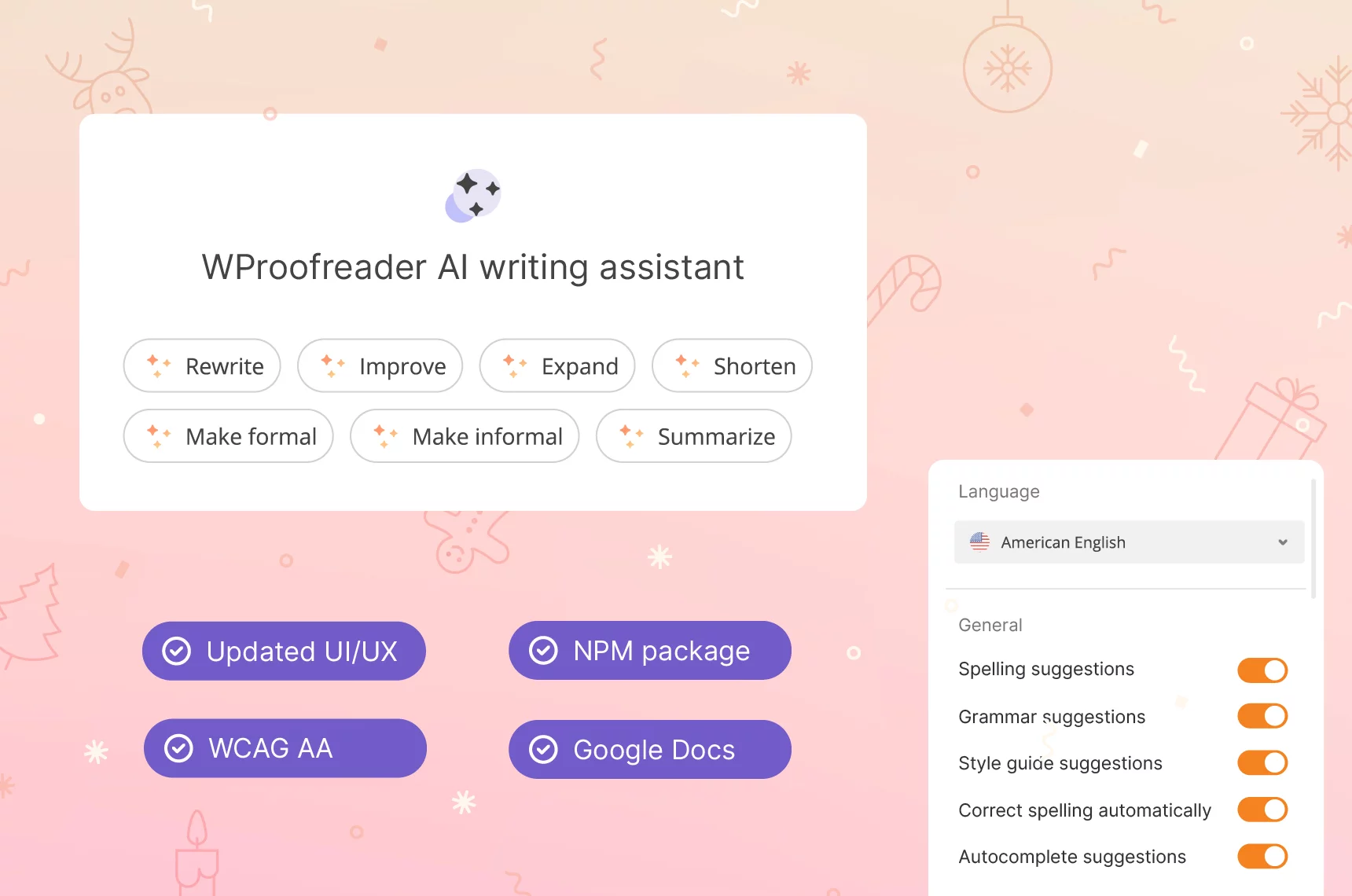
- Multilingual AI writing assistant 🪄 with custom prompts to reword text, change formality and enhance your writing
Try all these features now with our demo.
WProofreader AI writing assistant
Rewrite and text generation for business and individual users. Coming soon.
Wrap-up
With RedPenNet v2, we’ve finally reached the sweet spot. We took the best from two approaches — one gives high accuracy but is slow, the other is fast but a bit shallow. By combining them, we’ve created a hybrid system that gets the job done both quickly and accurately.
With this new version, WProofreader has become noticeably more accurate and helpful. While the previous model already had a solid grasp of context, this update brings more refined grammar checks, better style suggestions and improved handling of confusing phrases. These enhancements come from our new, custom-built dataset created by our in-house linguistic team. It’s still the WProofreader you know, just smarter and more precise in understanding what you’re trying to say.
Let’s revisit how RedPenNet’s new model performs in difficult cases, especially when stacked against other well-known spellcheckers:
| Issue | WProofreader | Sapling | Grammarly | Linguix |
| to staff → staff | Passed ✅ | Failed ❌ | Failed ❌ | Partially passed 🤔 |
| are → was | Passed ✅ | Passed ✅ | Passed ✅ | Partially passed 🤔 |
| spice free → spice-free | Passed ✅ | Failed ❌ | Passed ✅ | Passed ✅ |
| the him → him | Passed ✅ | Passed ✅ | Passed ✅ | Partially passed 🤔 |
| your → his | Passed ✅ | Failed ❌ | Passed ✅ | Partially passed 🤔 |
| will → would | Passed ✅ | Passed ✅ | Passed ✅ | Partially passed 🤔 |
| completely be → be completely | Passed ✅ | Passed ✅ | Passed ✅ | Failed ❌ |
WProofreader with the new AI-driven model catches both obvious grammar mistakes and subtle context-dependent errors that require real understanding.
However, there’s always a room for improvement and we are constantly working on new updates which will make your experience with WProofreader even better. Stay tuned!