
How do you feel about writing mistakes?
For some, they symbolize failure and remind them of a negative school experience. For others — represents invaluable insights. Regardless of which camp you belong to, there’s one common desire: to identify mistakes quickly, fix them and, ideally, not to repeat them further.
And this is precisely why text checkers exist.
Our mission at WebSpellChecker is to equip you with a solution that identifies writing errors fast and provides accurate suggestions. While this may sound simple, there are many complex operations behind the scenes.
Let’s pull back the curtain together and peek behind.
Main approaches to classifying writing errors
So, one task of text checkers like WProofreader is to properly categorize mistakes made by people. To an end, a tool should deploy a number of components responsible for various language aspects: spelling standards, semantic accuracy, punctuation rules, specific terminology and style guides.
Usually, it’s achieved by complex architecture with a mix of rules-based engines and trained AI models to recognize the specific terminology and the author’s choice. Otherwise, tools risk providing incorrect suggestions, which can lead to context misunderstandings, and diminish the clarity of user texts.
We get requests from clients about how exactly WProofreader classifies writing errors, because the topic is as old as time and still widely discussed by the community.
The theoretical foundation of error classification stems from linguistics. Don’t worry, we’ll try to avoid the complex terminology from textbooks 😁
| Category | Definition | Example |
| Morphology | Errors related to word forms | Using runned instead of ran |
| Orthography | Typos in words | Writing helo without the letter l |
| Syntax | Mistakes in sentence structure, including punctuation | Missing a comma after music: I love listening to music especially jazz |
| Semantics | Bugs are related to the words’ meaning | Using a word that doesn’t fit the context: affective instead of effective |
The linguistic aka traditional approach allows us to do more than just spot when something goes wrong. It helps us understand at what level of the language the error occurred. In this way, we can break down the error and see whether it’s related to the word choice, sentence structure or the text context.
Pit Corder, GEC and ERRANT vs the traditional approach
Linguist Pit Corder is the one who significantly contributed to the evolution of error classification methods.
He focused his efforts on studying errors that occur during language acquisition, unlike the linguistic approach. But why?
Corder pointed out that the traditional approach isn’t always clear-cut. Errors can often fall into more than one category, which makes them harder to identify precisely. For instance, the same mistake might be both morphological and syntactical, depending on the context. Because these two branches of linguistics work at the same language level, it is related to word spelling.
This led Corder to find a better way to sort out language mistakes. He noticed that traditional methods just found broken rules, but did not investigate how they appeared.
This work had a major impact on how we classify language mistakes today, especially as to the text-checking software.
Pit Corder identified four main categories of errors.
| Category | Definition | Example |
| Substitution errors | One language unit replaces another. For example, incorrect use of synonyms or a grammatically incorrect word form | He goed to the store instead of He went to the store |
| Omission errors | Language elements that should be present in a sentence are missing. These can be artifacts, prepositions, or endings | I going instead of I am going |
| Addition errors | These mistakes occur when extra elements appear in a word or sentence | She does not goes instead of She does not go |
| Disordering errors | It takes place when elements of a phrase are arranged incorrectly | What you are doing? instead of What are you doing? |
This approach focuses on analyzing the action that led to the error.
The next step in classification of writing errors involves Grammatical Error Correction (GEC), which draws inspiration from Pete Corder’s methodology. GEC is part of Natural Language Processing (NLP), the branch of AI that allows computers to understand people and communicate in their language. By leveraging NLP techniques, GEC identifies and corrects grammatical mistakes in writing. This approach has become widely used in grammar-checking tools.
GEC got inspiration from Corder’s methodology and deployed three categories of errors to make corrections easier.
| Category | Definition | Example |
| Replacement errors | This type of error happens when one word is replaced by another | dreamed instead of dreamt, depending on the English dialect |
| Omission errors | When a word is missing in a sentence, it leads to this kind of error | I’m going store instead of I’m going to the store (the necessary preposition is skipped) |
| Insertion errors | This error occurs when an extra word appears where it shouldn’t | He goes to to the store, where the second to is redundant |
GEC relies on this very approach as it helps to fix errors quickly without turning to specific language categories or other strict classifications. This approach stands in sharp contrast to traditional method, which focuses on examining the nature of errors. The key advantage of this classification is technical feasibility — it aligns with basic word processing principles, avoiding complex linguistic analysis that machines can’t effectively perform.
However, the bottleneck is that GEC doesn’t always consider context, which can sometimes lead to mistakes in corrections.
The situation has changed with the introduction of AI for GEC and the need for text annotation in model training and fine-tuning. Since different annotators flag errors using their own methods, which made it difficult to manage and compare multiple datasets. To solve this problem, ERRANT (ERRor ANnotation Toolkit) was created. ERRANT automatically identifies and labels errors in text using a unified standard. This means all texts will have errors marked consistently. As a result, working with various datasets and training error-correction programs has become much easier. This solution greatly simplifies the use of data for training GEC systems and enables consistent grammatical error analysis across different texts.
While Errant is built on GEC principles, it offers a more flexible and effective error classification system:
- F: the wrong form of the word has been used
- M: a necessary element in a word or sentence was missed
- R: the word or phrase needs to be replaced
- U: the word or phrase is redundant
- D: a word is wrongly derived
It means that ERRANT doesn’t just simplify text-checking; it also enhances it with new capabilities. By integrating GEC with its updated error classification, ERRANT can handle a wider range of language issues. This improves the overall quality of the text and makes it easier for readers to understand.
Congrats 🎉 Now you know the main ways to categorize writing errors, let’s see how they work in real life. But let’s go ahead.
Grammar, spelling, and style: the text checkers approach
Take the sentence:
Yesterday, I goed to the park with my friends.
This is a controversial case as it can fall under multiple categories.
From a linguistic approach, we’re dealing with a morphological mistake. It’s a common mistake where someone applies regular verb rules (-ed ending) to an irregular verb. However, one could also view it as an orthographic mistake if they focus on the incorrect verb form used in the context.
Looking at it through Corder’s lens, this is a classic substitution error. The writer had replaced the correct form went with an incorrect one. Similarly, in GEC terms, this would be labeled as a replacement error, where one word form needs to be swapped for another.
The ERRANT system would put this mistake in category F (Form), as it involves using the wrong form of the verb go.
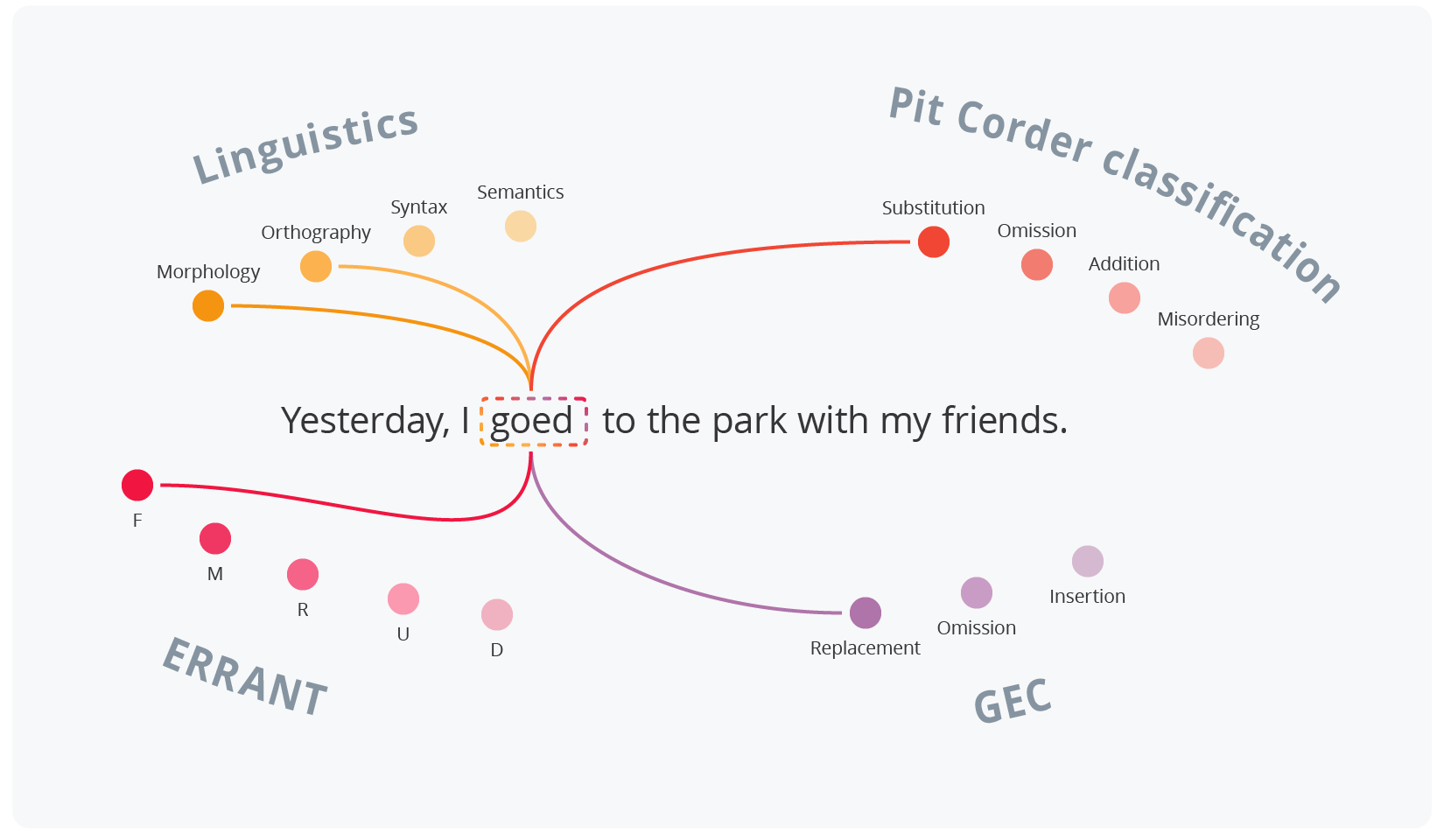
While these approaches might sound different, they all help us understand deeply and fix the same basic problem.
This example illustrates Corder’s idea that the same error can fall into different categories depending on the context of its occurrence and interpretation. Remember that when dealing with language errors.
So, what about text checkers?
For the sake of user convenience, the industry typically categorizes errors into three main groups: grammar, spelling, and style. Each type gets a specific color of underline, which helps users quickly identify issue areas in the text.
To visualize, text editors underline errors with different colors. For example, at WebSpellChecker, we use red, blue, and orange.
- Grammar relates to the misuse of language rules. This category includes morphology, sentence structure as well as punctuation errors.
- Spelling takes place when people make typos.
- Style errors involve the use of language. For instance, if someone repeats the same words or phrases too frequently, the text can appear unnatural. Logically, this category includes semantic, pragmatic, and lexical errors.
And yes, this may look like a simple way to categorize user mistakes, but some tools go beyond and extend the set of error marks.
Grammarly, Sapling AI or ProWritingAid?
There’s a famous Latin saying: Quot homines, tot sententiae, which means “there are as many opinions as there are people.” This statement perfectly captures the situation in the digital proofreading market with solutions for all tastes.
For our analysis, we compared free versions of several leading solutions and their approaches to error categorization.
The text example:
I goed to the cinema yestreday. The movie a strong impression made on me. I guess the actors played very good in it, and the cameraman did a nice job too.
Let’s break down the mistakes for the record:
- goed: It can be either a spelling or a grammatical error. The correct form is went. We will explore how text checkers handle such a controversial case.
- yestreday: This is definitely a spelling error. The right version is yesterday.
- The film a strong impression made on: This is a syntax error of incorrect word order. Unless you’re intentionally trying to speak like Yoda from Star Wars 🤓 the correct order should be The film made a strong impression on.
- very good: This is a semantic error; good is incorrectly used as an adverb. The correct form should be very well.
- cameraman: While not grammatically incorrect, this term can be considered pragmatically inappropriate. It’s often viewed as a non-inclusive language; a more inclusive term would be camera operator or camera person.
Grammarly
Grammarly organizes its suggestions into four main categories: correctness, clarity, engagement, and delivery.
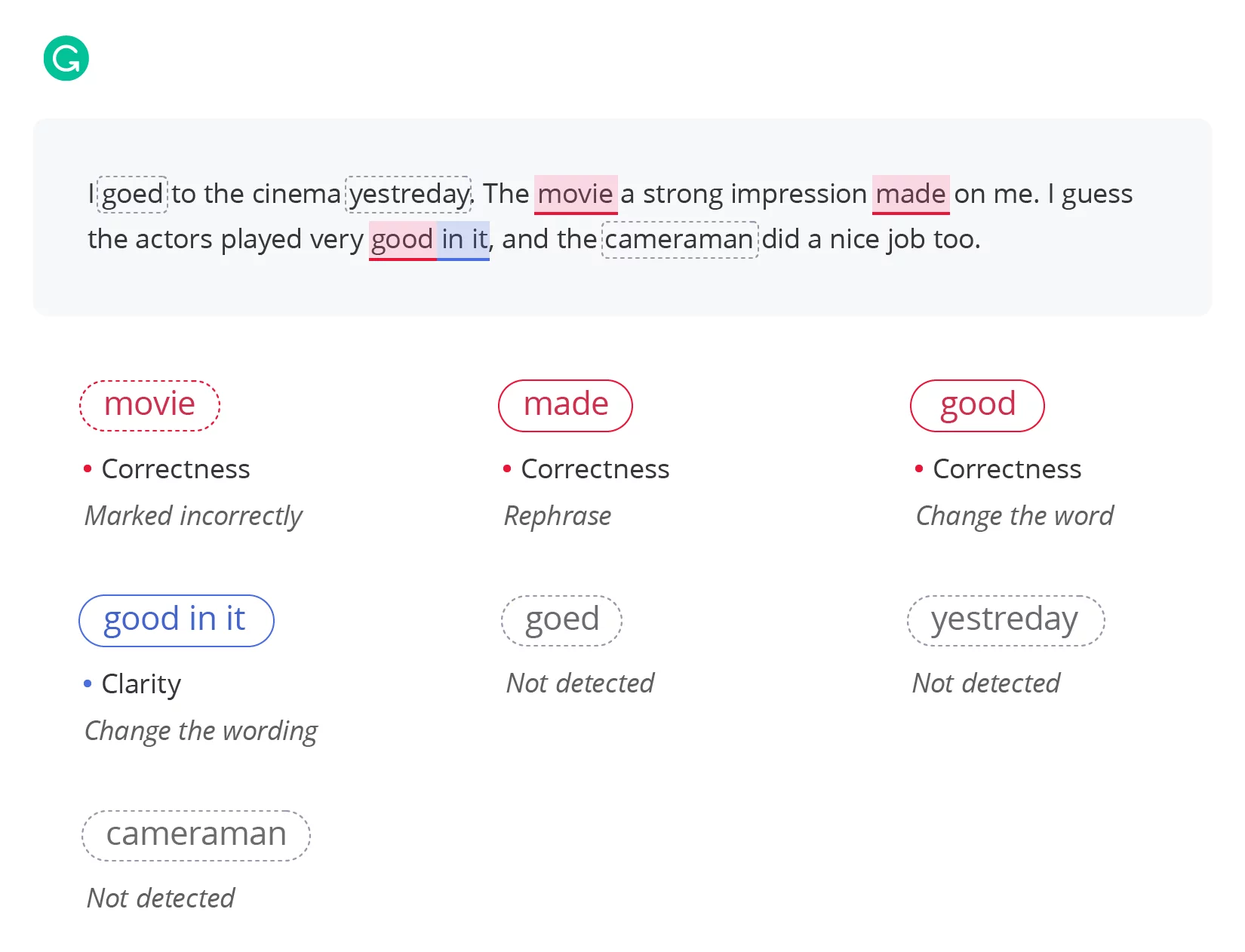
As of October 2024, Grammarly identified two out of five mistakes. It didn’t catch all the aspects of the sentence grammar and semantics in this very case, but it’s probably not the quote.
Also, in the second sentence, Grammarly marks movie and notes that a preposition is missing after this word — this may be the point as the sentence structure is broken and Grammarly strives to fix it the way it can.
In addition, for some types of categories (e.g., clarity), a limited number of corrections per day are available for free use — a bit irritating…
Sapling AI
Sapling AI categorizes errors into five broad categories: grammar, spelling, or punctuation, fluency/style and other. Actually, there’s no official color classification for errors used by Sapling AI. So, the table is based on our own observations after testing the tool.
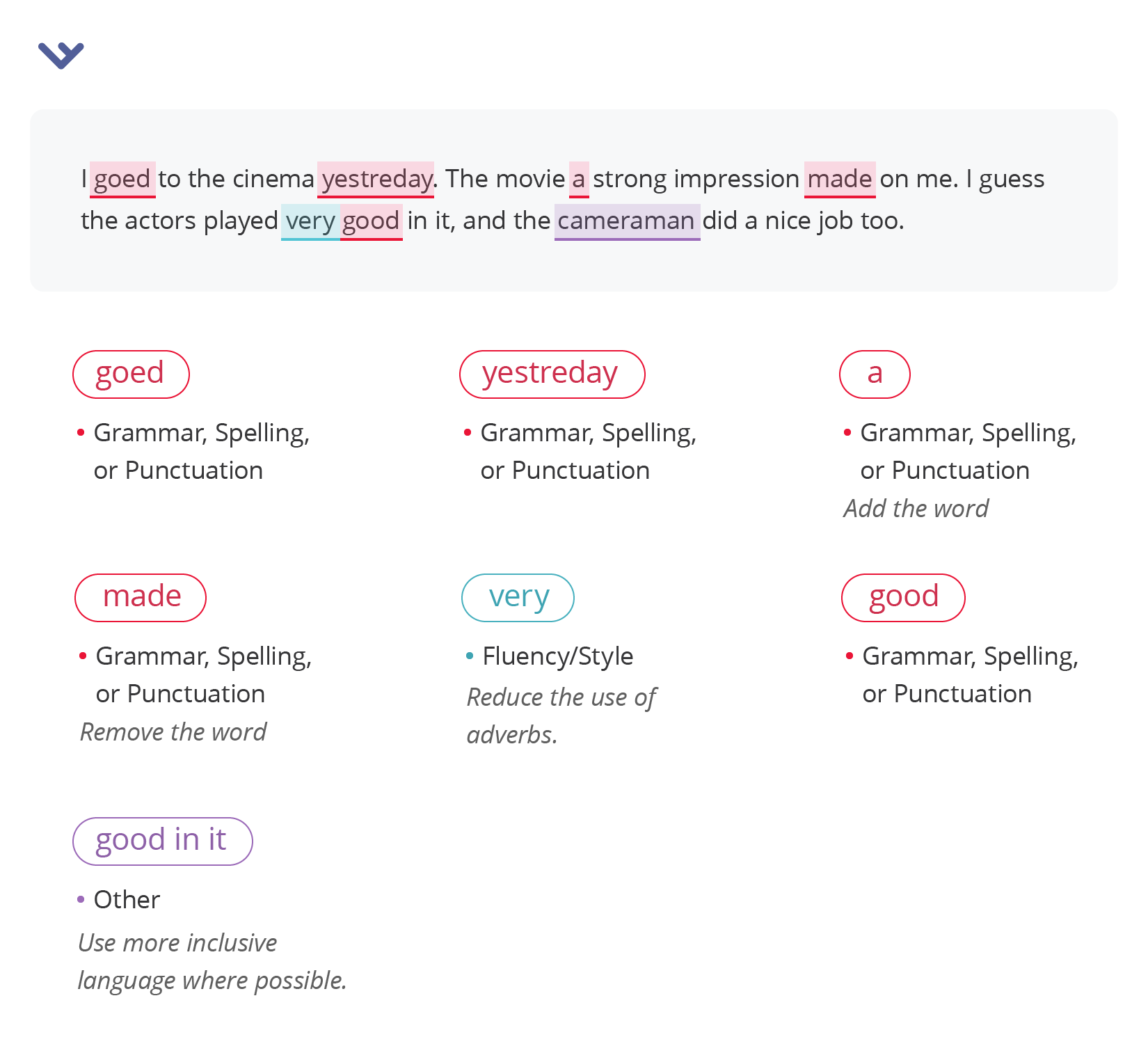
Overall, Sapling successfully detects all the errors presented in the text. But, we noticed that it corrected issues separately, which may complicate the editing process. The possible reason — the proofreader’s model does not consider the sentence as a whole. So, it struggles to connect mistakes within the context.
ProWritingAid
In ProWritingAid, errors fall into three categories: spelling, grammar and composition.
Additionally, this tool features determining writing style. This function provides personalized recommendations that align with the user’s context. For our comparison, we will stick to the general style.
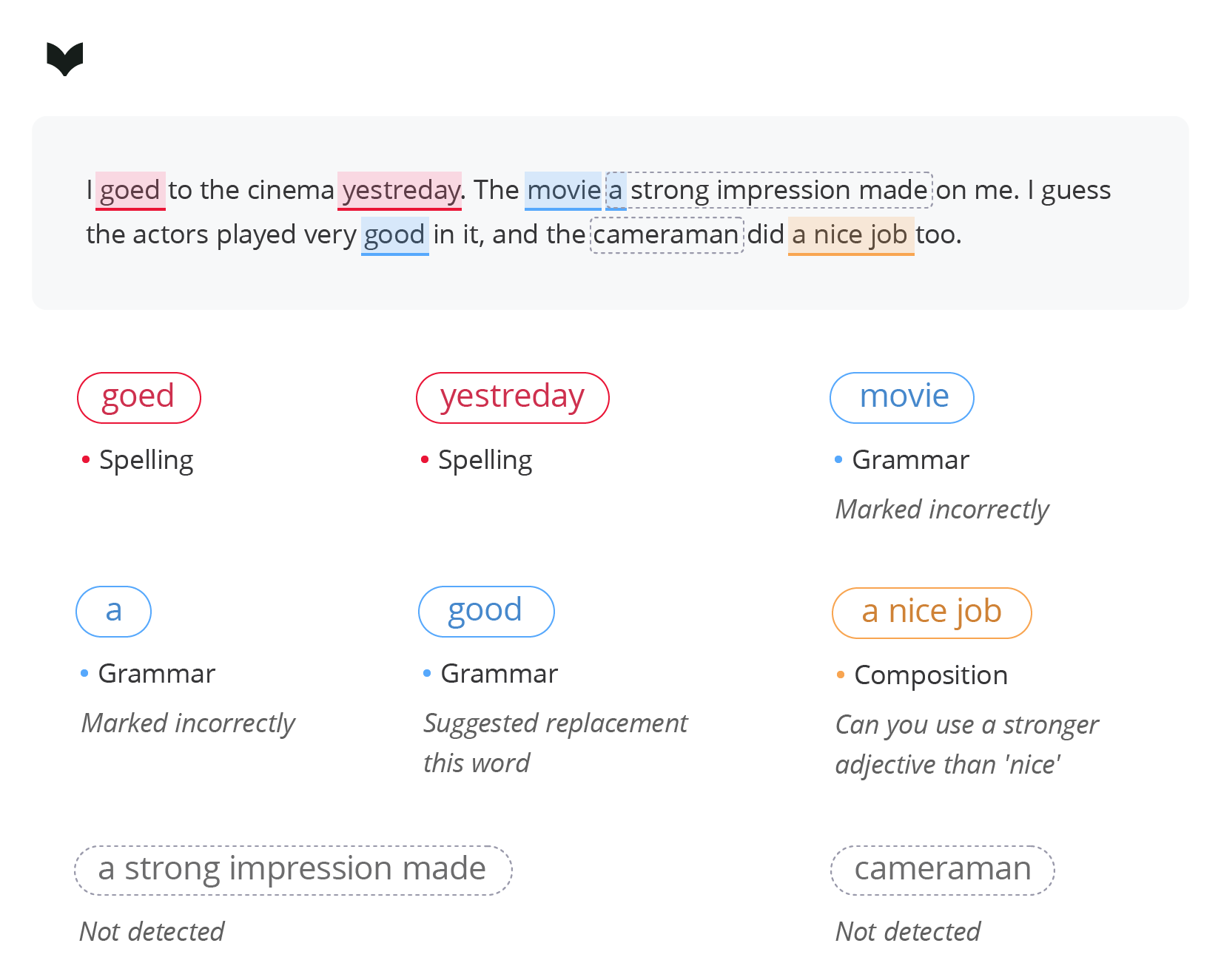
ProWritingAid nails four out of five errors — pretty impressive, right? It identifies both spelling and grammar issues, but doesn’t provide complete fixes. We wish it had found the semantic error in the second sentence, but it did offer an alternative. Maybe the technology behind this tool didn’t fully grasp the context in this case.
WProofreader’s approach to categorization
WProofreader is a multilingual tool for checking spelling and grammar in texts. We offer two solutions for organizations and individuals: WProofreader SDK and WProofreader browser extension.
WProofreader combines traditional and modern approaches to error classification for a better performance. At the UI level, you can see colorful underlines:
- Red: Spelling errors
- Blue: Grammar, punctuation, or contextual errors
- Orange: Stylistic errors, including non-inclusive language, coarse vocabulary, and inappropriate slang
Actually, we partially apply a linguistic approach and, partially, Pit Corder’s idea, that a single error can belong to multiple categories by using a mix of rules-based and AI engines. This lets us analyze texts deeply and offer more accurate suggestions.
For the AI-based GEC engine, we developed RedPenNet, an in-house architecture. RedPenNet deploys pre-trained models for error detection and offers corrections. Then, during post-processing, the algorithm determines which category the suggestion belongs to.
Key features of RedPenNet:
- Context analysis: RedPenNet analyzes text at the sentence level, considering the context of word usage.
- Interconnected error detection: We use an autoregressive method for the checking process. By doing so, the model can identify related errors and make comprehensive corrections later.
- Predictable corrections allow us to anticipate how changes will affect sentence meaning and prevent new errors from appearing.
RedPenNet offers a custom approach to text validation. Our model provides more accurate, context-aware, and comprehensive error correction than regular rules-based engines. But still, the model tends to skip issues or showcase a biased output — the AI is such a black box 🥲 That’s why we offer our clients a mixed approach, just to be sure that you get the most out of our products.
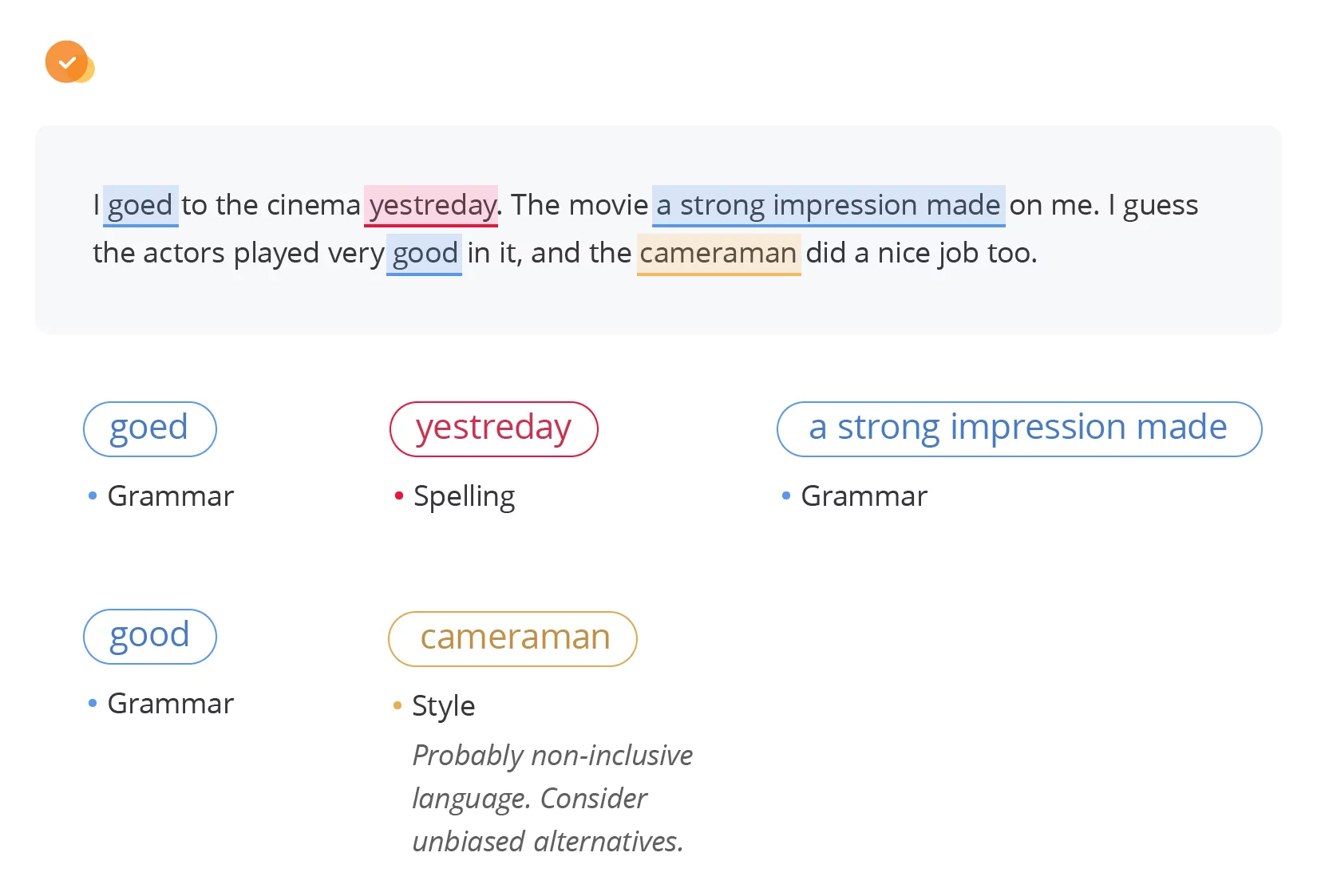
WProofreader’s mixed engine detected all mistakes. And plus, our tool went beyond simple spell-checking to more nuanced issues like non-inclusive language. Actually, this is proof of the capabilities you can get if you opt for a mixed configuration.
Among a wide range of features, in a WProofreader bundle there are:
- Real-time correction in 20+ languages, including AI-based English, German, and Spanish.
- Autocorrect and autocomplete features for English and dialects
- Automatic language detection
- Organization-wide and user custom dictionaries
- Specialized medical lexicon for English, Spanish, French, and German
- Legal lexicon is available for English and its dialects
- Inclusive language recommendations
Remember, if you need to quickly change the entire text at once, you can use our new WProofreader AI writing assistant 🪄 It’s geared to help you effortlessly transform your text. The WebSpellChecker team invested a lot in creating and fine-tuning a set of preset prompts for common text adjustments like text rewrite, size change or style shift. AI writing assistant is available in all versions of WProofreader ☺️
The AI writing assistant 🪄 supports the following languages: English, German, Spanish, Portuguese, French, Dutch and Swedish.
WProofreader AI writing assistant
Rewrite and text generation for business and individual users.
Explore moreConclusion
- We’ve reviewed the main approaches to error categorization: the linguistic aka traditional one, Pit Corder’s and ERRANT for GEC.
- Based on this information, we compared the performance of popular grammar and spell checkers. Grammarly, Sapling AI and ProWritingAid show out-of-the-box practices for classifying errors. But, chances are that they’re based on the principles of the linguistic approach.
- The tools we tested caught most errors but failed to cover all aspects of grammar and semantics in a test sample. Additionally, they struggle with grasping the full context and linking related mistakes.
- WProofreader effectively detected all types of errors. It provided comprehensive replacements while understanding the sentence context as a whole. The tool also works with inclusive language, helping users adhere to modern non-discriminatory standards.
To learn more about the capabilities of WProofreader, feel free to contact us.

 Tech
Tech

 Français
Français


 Linguistics
Linguistics Deutsch
Deutsch